
We have already familiarized ourselves with the concept of self-attention as implemented by the Transformer attention mechanism for neural machine translation. We will now be shifting our focus to the details of the Transformer architecture itself to discover how self-attention can be implemented without relying on the use of recurrence and convolutions. In this tutorial, […]
Explain the need for Positional Encoding in Transformer models (with Example)
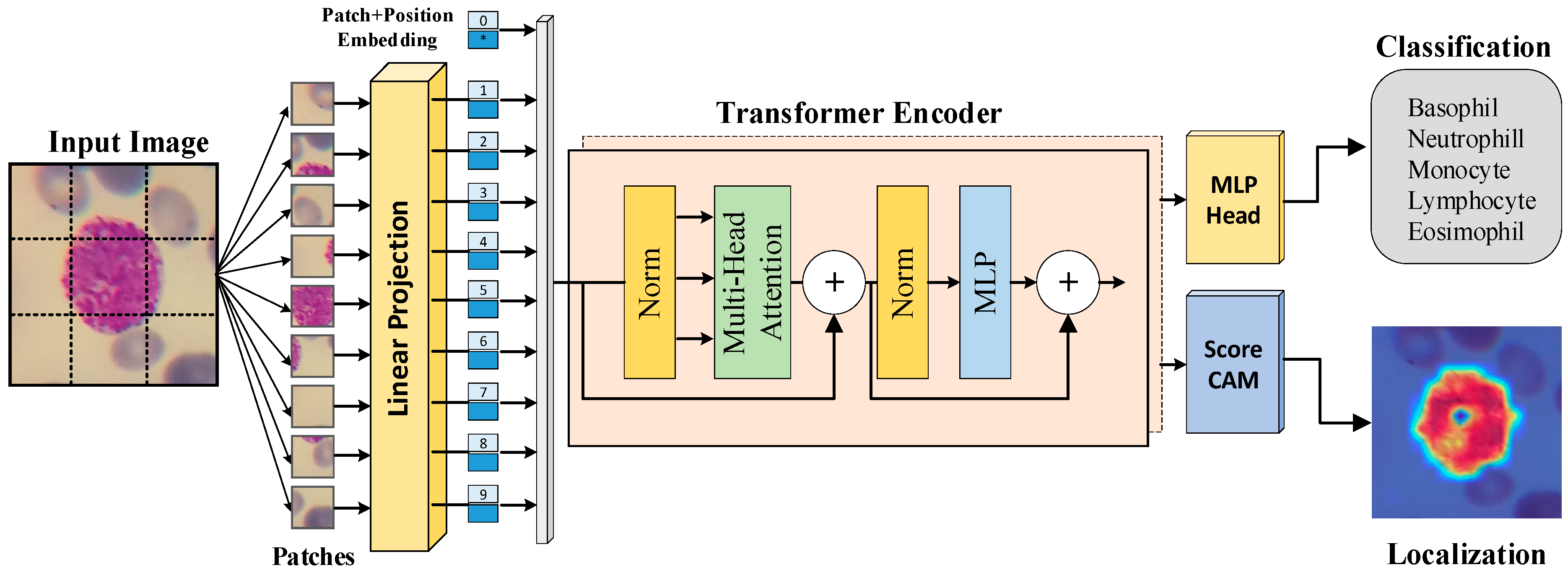
Diagnostics, Free Full-Text
Transformer (machine learning model) - Wikipedia
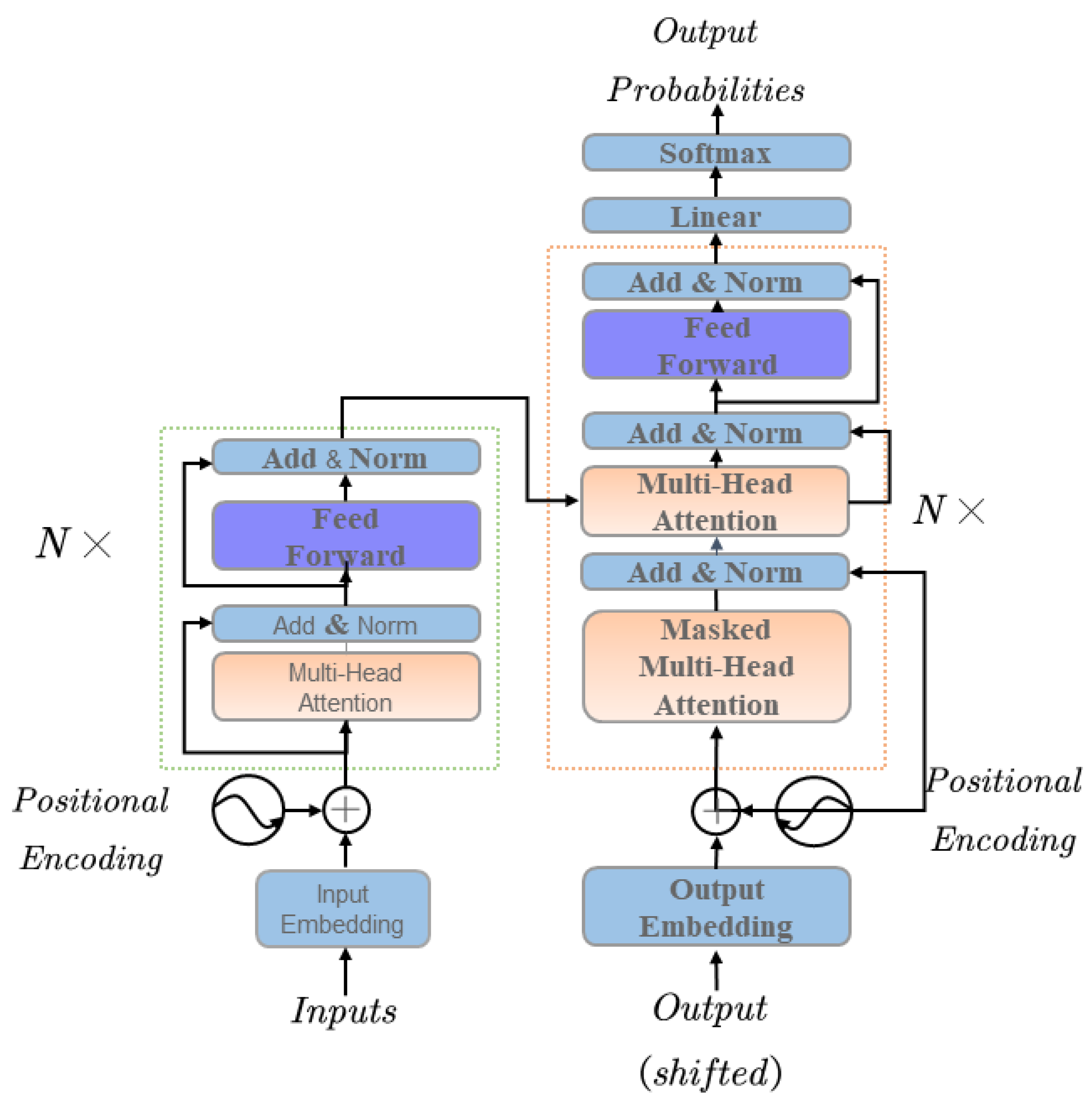
Applied Sciences, Free Full-Text

TransPolymer: a Transformer-based language model for polymer property predictions

The Transformer Model
The power of wide transformers models - TechTalks
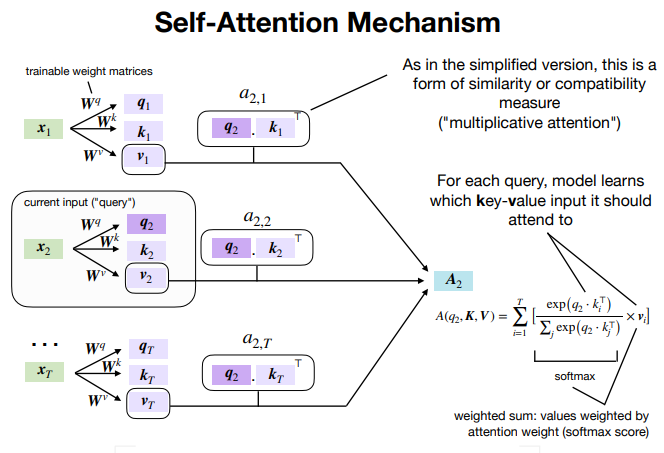
Attention Is All You Need: The Core Idea of the Transformer, by Zain ul Abideen

Generative pre-trained transformer - Wikipedia
Build a Transformer in JAX from scratch: how to write and train your own models
What Is a Transformer Model?
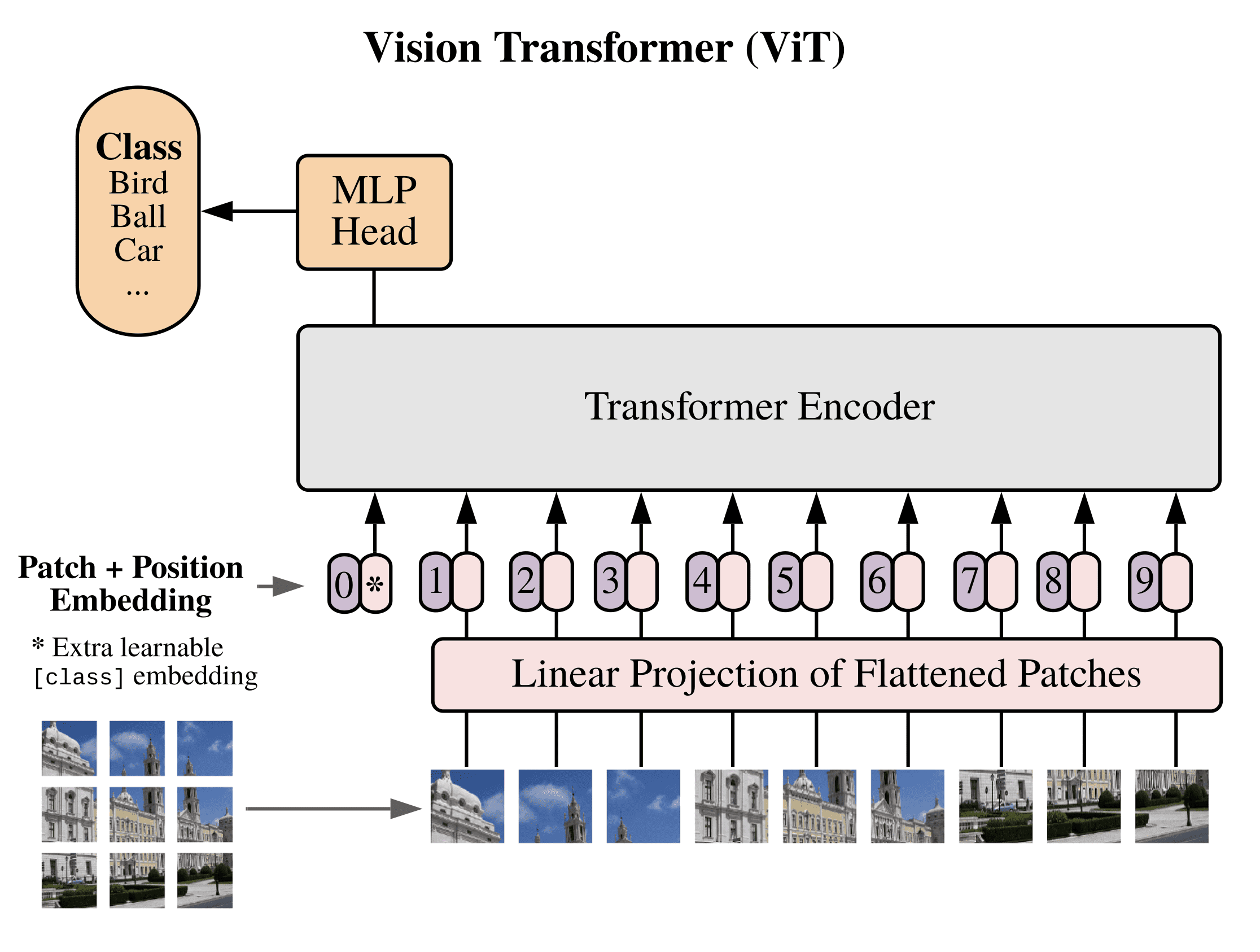
The Vision Transformer Model





